時をかけるイラストを生成できるPaints-Undoを使ってみた
イラスト作成過程をタイムラプス撮影したかのような動画が生成可能な「Paints-Undo」を使ってみましたので備忘ログに残します。

目次
インストール前に
動画を使用するため「FFmpeg」をインストールする必要があります。
「FFmpeg」のインストール手順は下記備忘ログを参照してください。
インストール手順
「Paints-Undo」は下記GitHubのものを使用します。github.com
インストールした環境は、Windows11、Python3.10です。
次に手順を説明します。
① コマンドプロンプトを開き、適当なフォルダで下記コマンドを実行。
※この例では、"D:\work"フォルダを使用しています。
D:\work> git clone https://github.com/lllyasviel/Paints-UNDO.git
② クローンしたフォルダに移動。
D:\work>cd Paints-UNDO
③ オリジナル環境を汚したくないので、VENVを使って仮想環境を構築します。
※この例では、仮想環境の名前は"venv"としましたが、なんでもOKです。
D:\work\Paints-UNDO>python -m venv venv
④ 仮想環境をアクティベート(実行)。
D:\work\Paints-UNDO>venv\Scripts\activate
仮想環境が立ち上がると、コマンドラインの先頭に(venv)が付きます。
(venv) D:\work\Paints-UNDO>
⑤ PyTorchをインストールします。
(venv) D:\work\Paints-UNDO>pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
⑥ Triton(Python3.10用)をインストールします。
(venv) D:\work\Paints-UNDO>pip install https://huggingface.co/madbuda/triton-windows-builds/resolve/main/triton-2.1.0-cp310-cp310-win_amd64.whl
※私の環境の場合、Paints-Undo起動時に下記エラーが発生して動きませんでしたのでインストールしました。
import triton # noqa
^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'triton'
⑦ xformersをインストールします。
(venv) D:\work\Paints-UNDO>pip install xformers
⑧ 最後にrequirements.txtに記載されているライブラリ群をインストールします。
(venv) D:\work\Paints-UNDO>pip install -r requirements.txt
以上でインストール作業は終了です。お疲れさまでした (^^)/
Paints-Undoを使う
起動
下記コマンドでPaints-Undoを起動します。
なお、初回起動のみ、各種データをダウンロードするようで結構時間がかかります。
(venv) D:\work\Paints-UNDO>python gradio_app.py
コマンドプロンプトの最後に下記内容が表示されたら起動OKです。
注)コマンドプロンプトは閉じないように!
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Webブラウザを起動して下記URLにアクセスするとGUIが表示されます。
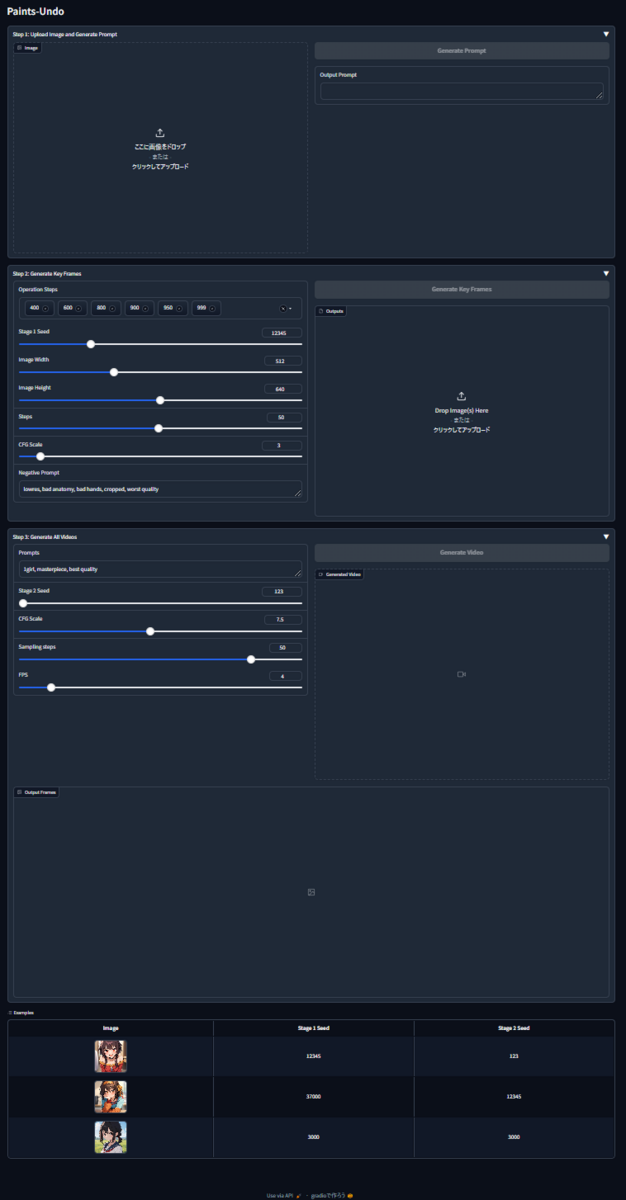
とりあえず使ってみる
動画を生成するまでの流れはGUIにも記載されていますが、下記3ステップです。
- Step 1: Upload Image and Generate Prompt (画面上部)
- Step 2: Generate key Frames (画面中央部)
- Step 3: Generate All Videos (画面下部)
Step 1: Upload Image and Generate Prompt
自分で画像をアップロードするか、Examplesのサンプル画像をクリックしてください。
アップロードすると画像が表示されますので、右側の「Genarate Prompt」ボタンをクリックします。
画像解析した後、Stable Diffusionなどをお使いの方には見慣れたプロンプトが「Output Prompt」に表示されます。
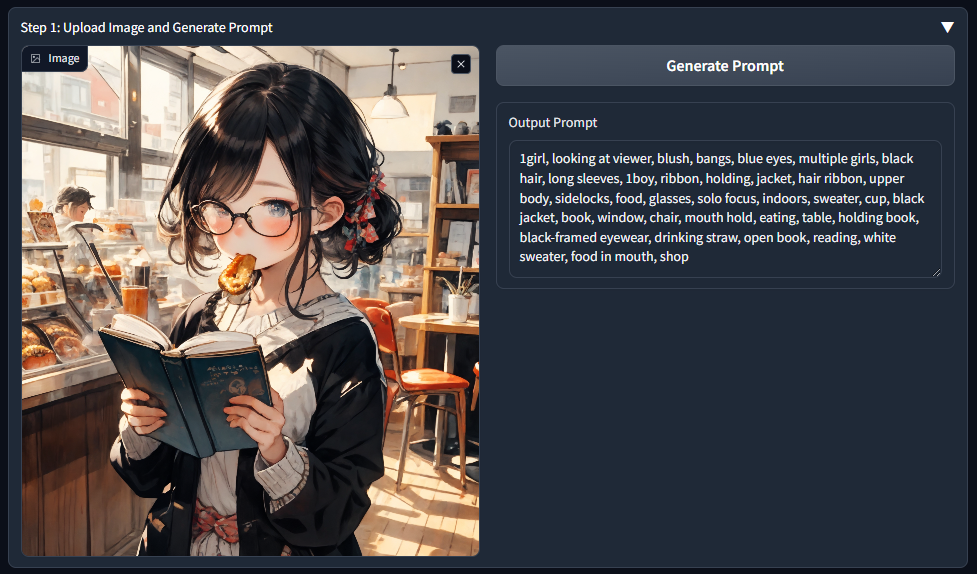
Step 2: Generate key Frames
アップロードした画像サイズは512x512なので、「Image Height」をデフォルトの600から512に変更します。※忘れやすいです (^^;
そして、「Generate Key Farmes」ボタンのクリックすると8枚の画像が表示されます。
Pains-Undoは、白紙から1000回書き換えた流れを生成しています。
そのため、1枚目がオリジナル、8枚目が白紙、2~7枚目は「Operation Steps」で指定した回数の画像となっています。
ちなみに、処理時間はRTX3060(12G)で36秒でした。
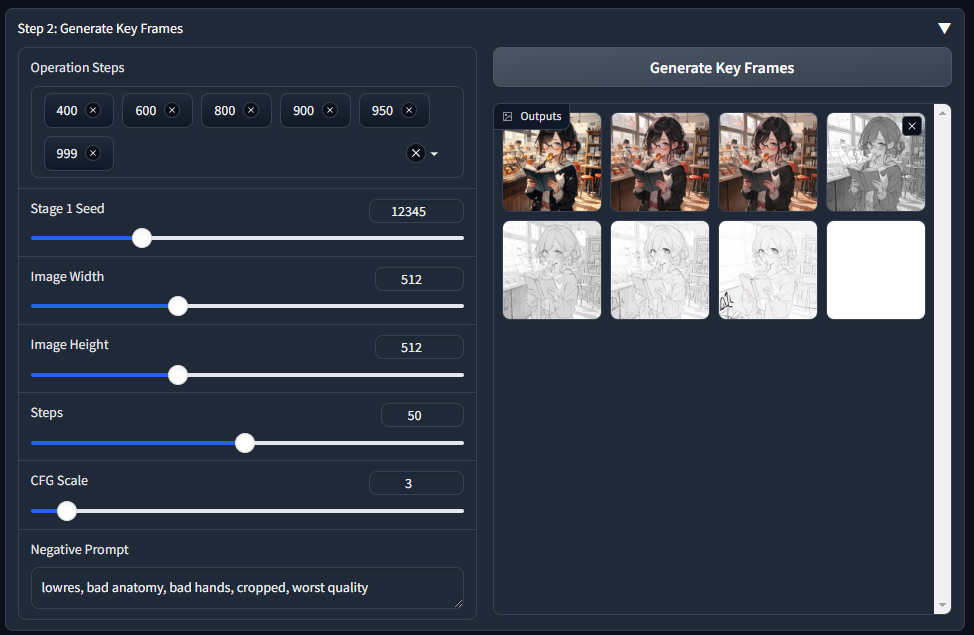
Step 3: Generate All Videos
最後のステップは「動画生成」です。「Genarate Video」ボタンをクリックすると処理が始まります。
ちなみに、RTX3060(12G)で750秒、RTX4090は160秒(やっぱり速い!)でした。
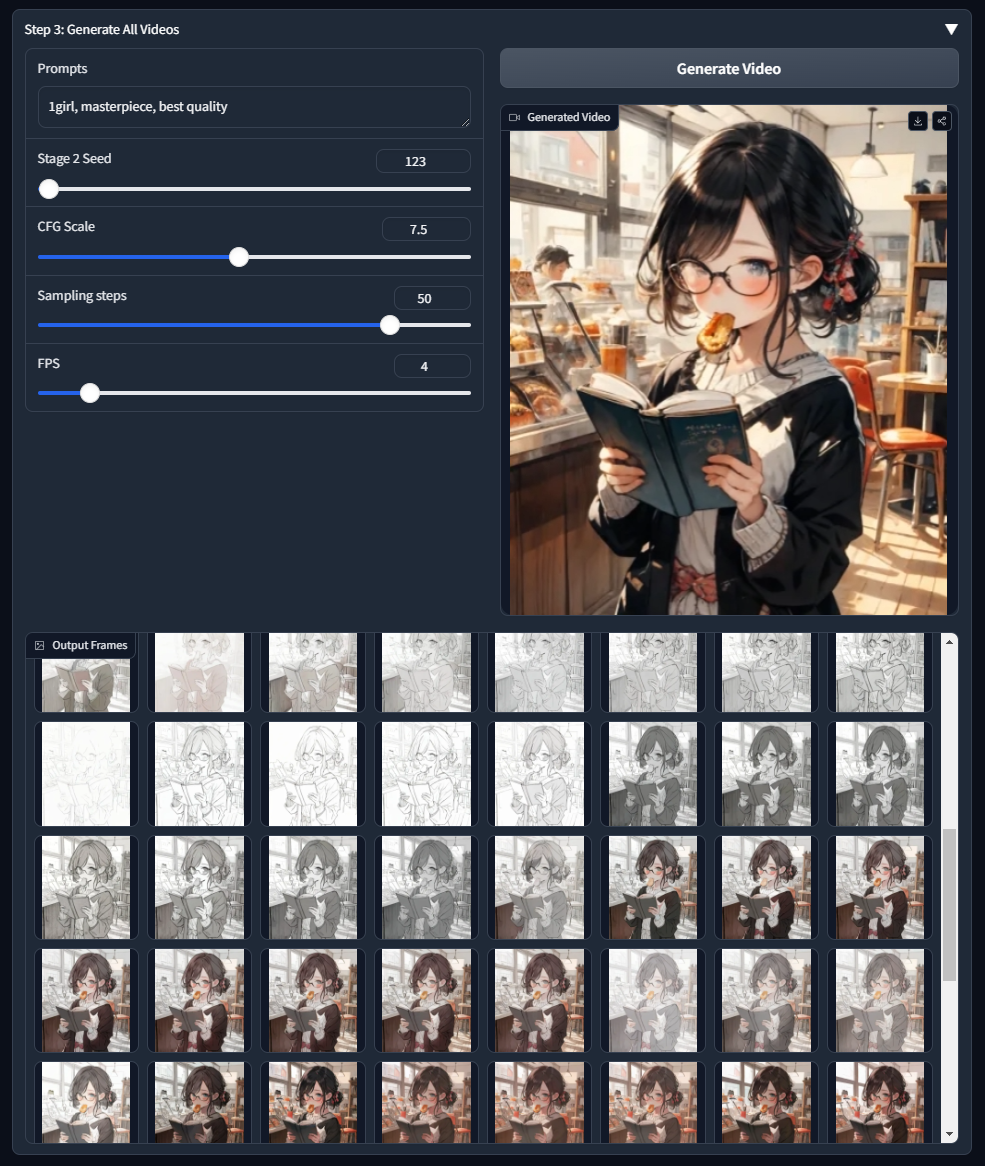
動画はこんな感じです。
あとがき
今回はデフォルト設定のみの確認でしたが、プロンプトやパラメータを変更すると自然な逆再生動画になりそうな雰囲気ですね。
Paints-Undoを「何に使うか?」という疑問は残りますが、絵を学ぶ際はラフな絵から徐々に描き込んでいく過程などが参考になるのではと感じました。
AIの進化恐るべしです (^^;
モノクロームな思い出を色鮮やかにするDeOldifyを使ってみた
「色づく世界の明日から」的なStable Diffusion WebUIの拡張機能「DeOldify」の動作確認をしてみましたので備忘ログに残します。

目次
インストール前に
動画を使用する場合は、「FFmpeg」をインストールする必要があります。
「FFmpeg」のインストール手順は下記備忘ログを参照してください。
インストール手順
「DeOldify」は下記GitHubのものを使用します。
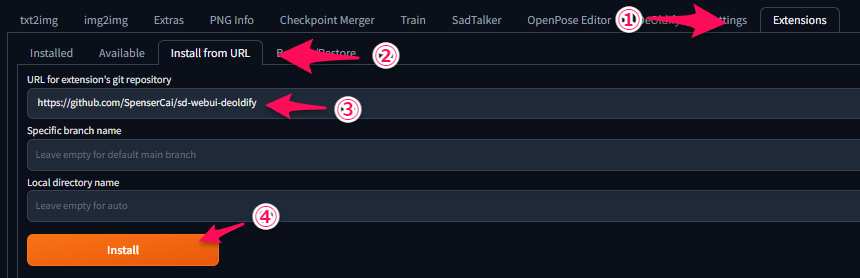
①「Extensions」タブをクリック
②「install from URL」タブをクリック
③「URL for extension's git repository」に上記URL(https://github.com/SpenserCai/sd-webui-deoldify)を入力
④「Install」ボタンをクリック
set COMMANDLINE_ARGS= --disable-safe-unpickle
⑥ StableDiffusionを再起動
⑦ タブに「DeOldify」が追加されている
以上でインストール作業は終了です。
モノクロ画像をカラー化
1. 手順
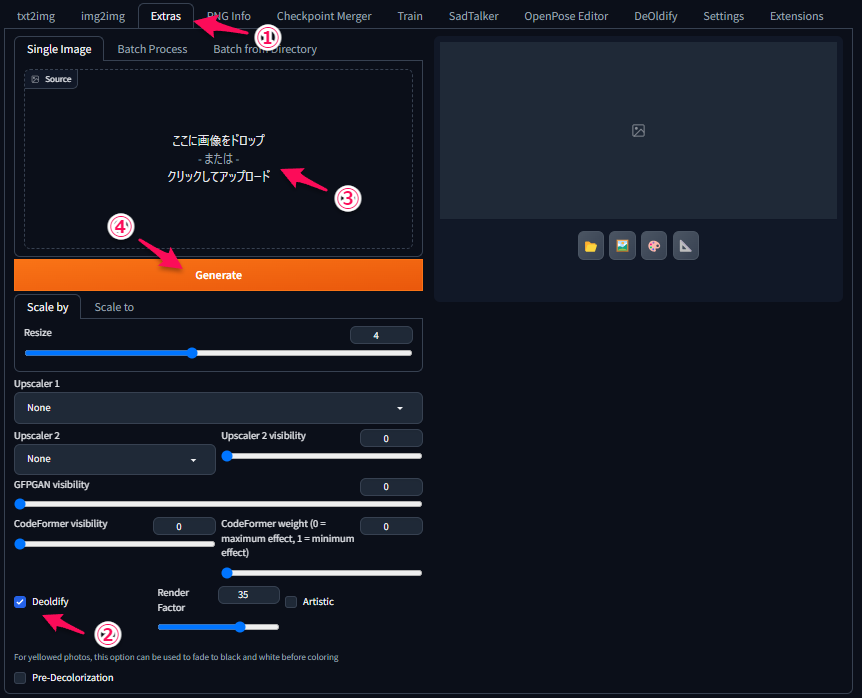
①「Extras」タブをクリック
②「DeOldify」にチェック
③「ここに画像をドロップーまたはークリックしてアップロード」に変換したい画像を設定
④「Generate」をクリック
2. 変換例

3. パラメータ
① Render Factor:色合いを調整
② Artistic:チェックを入れると少し鮮やかに
③ Pre-Decolorization:黄ばんだ写真を使用する際にチェックを入れる
「Render Factor」と「Artistic」の比較

モノクロ動画をカラー化
1. 手順
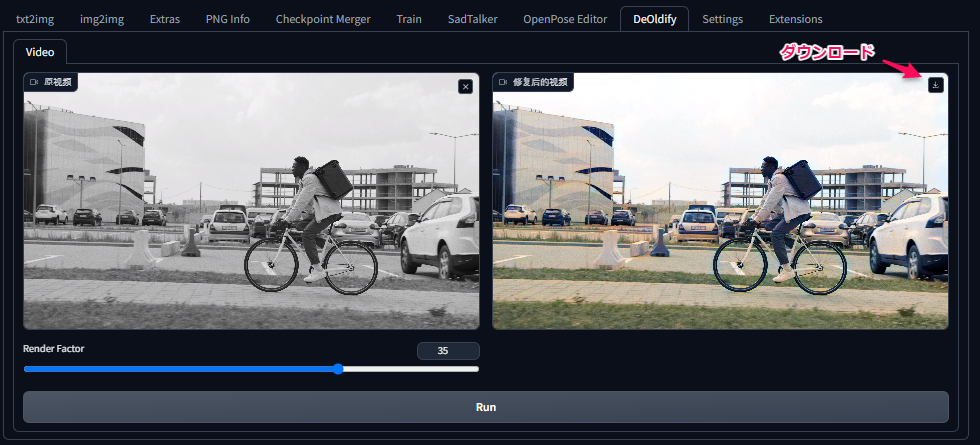
①「DeOldify」タブをクリック
②「ここに画像をドロップーまたはークリックしてアップロード」に変換したい動画を設定
③「Run」をクリック

※FFmpegをインストールしておく必要があります
2. 変換例
「ダウンロードボタン」をクリックすると変換後の動画がダウンロードできます。
あとがき
モノクロはモノクロで味があるのですが、カラー化することで情報量が増えてより臨場感が増すのはいいですね~
小さい頃の写真を引っ張り出して思い出に浸ろうと思います (^^)/
VALL-E-X(音声生成AI)が気になったので使ってみた
音声生成AIの「VALL-E-X」の基本機能の確認とハマりポイントがありましたので備忘ログに残します。

目次
インストール
下記アプリケーションやライブラリをインストールします。
なお、Windows11を前提に作業を進めます。
- FFmpeg
- CUDA12
- VALL-E-X
- PyTorch2.0
1. FFmpeg
下記サイトからWindows版のFFmpgeをダウンロードします。
ffmpeg.org
Windowsを選択し、「Windows builds by Btbn」をクリック。
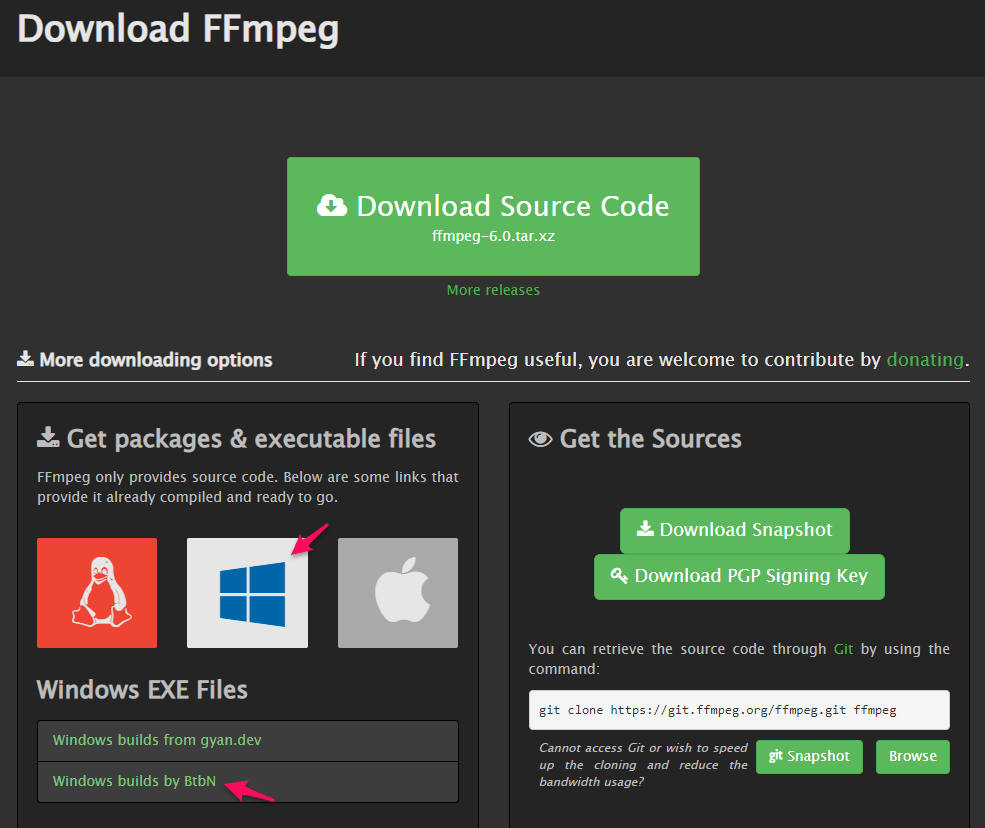
「ffmpeg-master-latest-win64-gpl.zip」をクリックしてダウンロード。
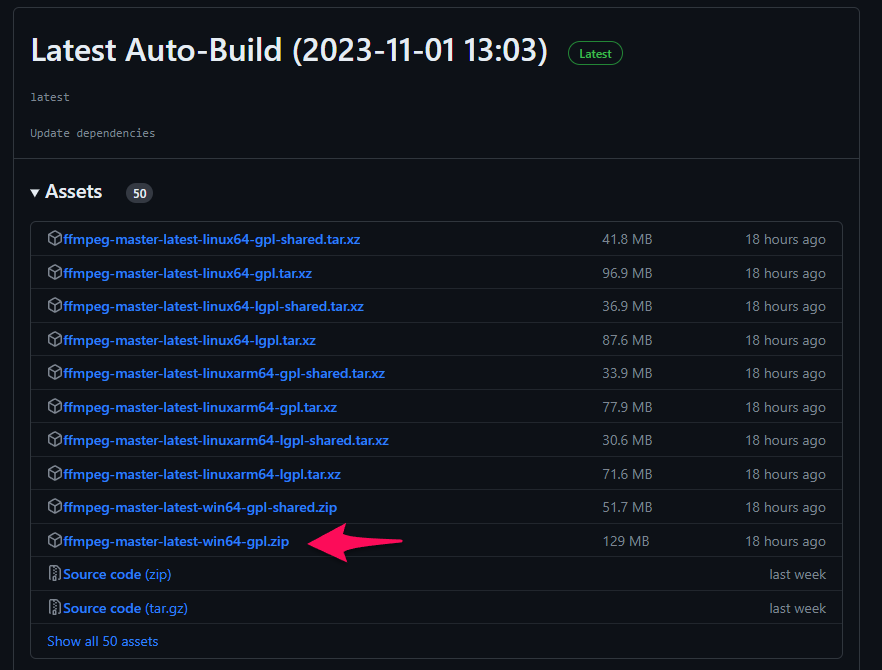
ダウンロードしたファイルを展開(解凍)します。
展開すると、「ffmpeg-master-latest-win64-gpl」フォルダ内に下記ファイル類が生成されていることを確認してください。
ffmpeg-master-latest-win64-gplを適当なフォルダに移動させてパスを通します。パスの通し方は「環境変数」の「Path」に「ffmpeg-master-latest-win64-gpl」を設定します。
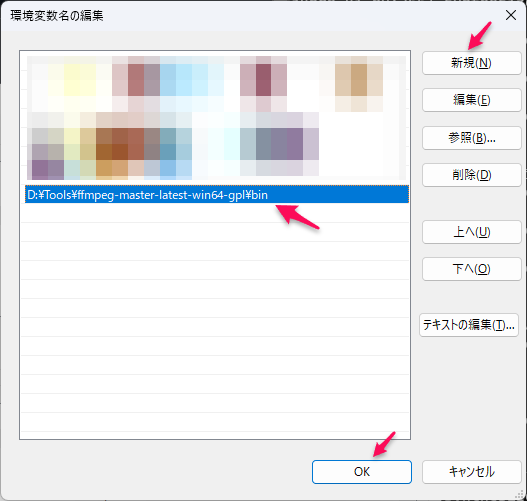
まず、「環境変数の編集」を開き、「環境変数」の「編集」ボタンをクリック。
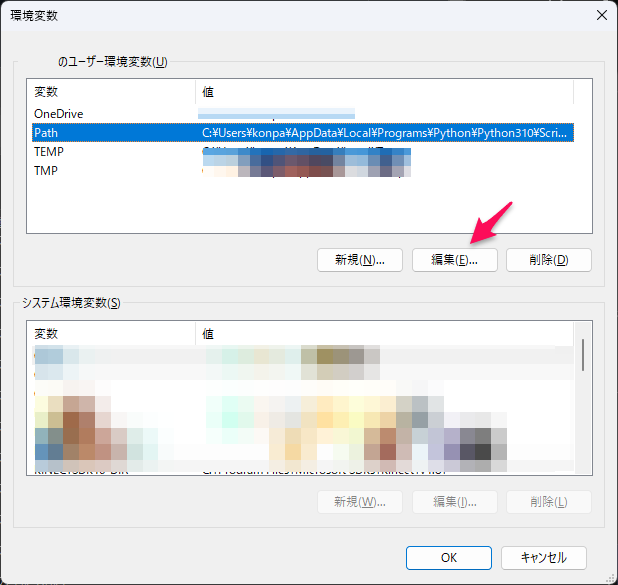
「環境変数名の編集」ダイアログにて、「新規」ボタンをクリックして、ffmpegのフォルダを追加し、「OK」ボタンをクリック。ffmpegフォルダ名は「bin」まで必要なので注意してください。
2. CUDA12.0
nvidia公式のCUDA Toolkit 12をダウンロード。
http:// https://developer.nvidia.com/cuda-12-0-0-download-archive
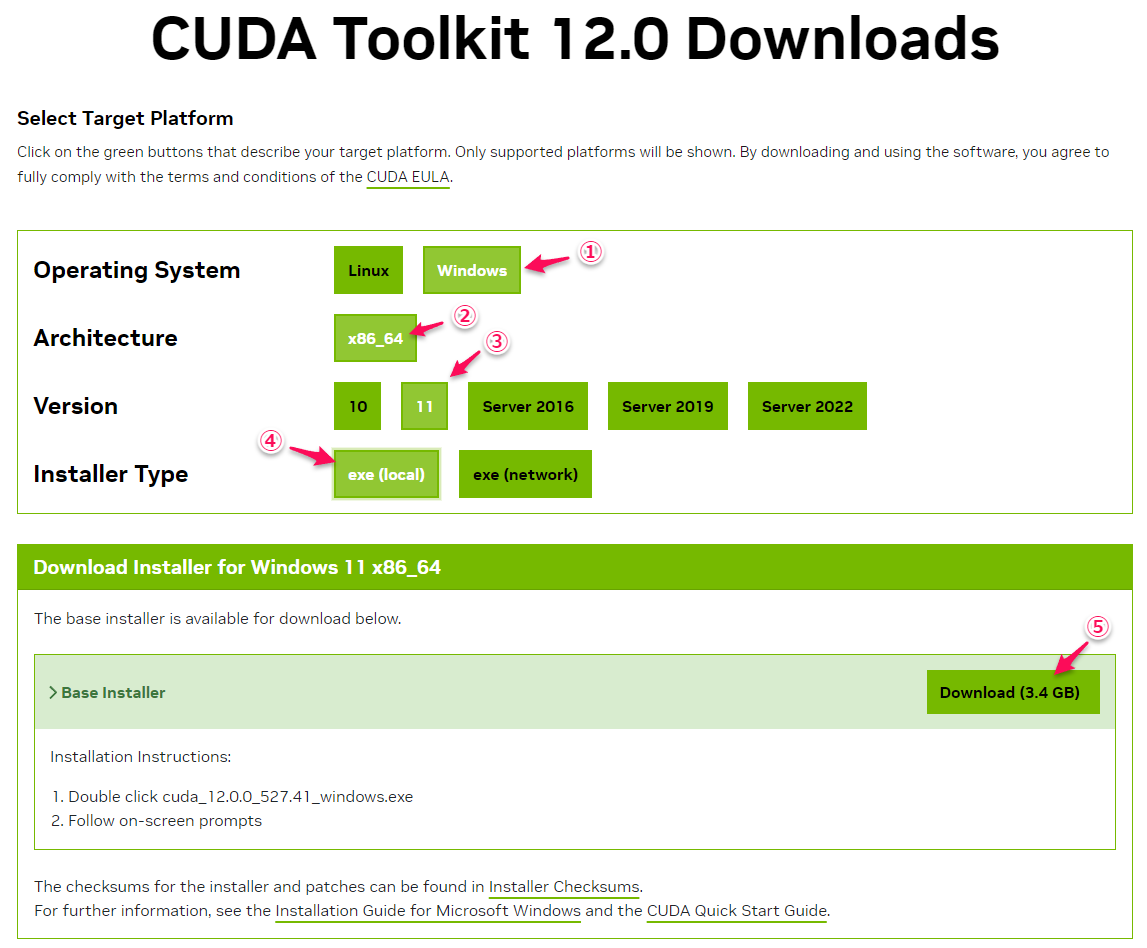
① 「Windows」をクリック
② 「x86_64」をクリック
③ 「11」をクリック(Windows11なので)
④ 「exe (local)」をクリック ※networkを選択しても問題ありません
⑤ 「Download(3.4GB)」をクリック ※大きいですね (^^;
あとは、ダウンロードしたファイルを実行するだけでOKです。
3. VALL-E-X
以下のGitHUBからファイル一式をクローンします。
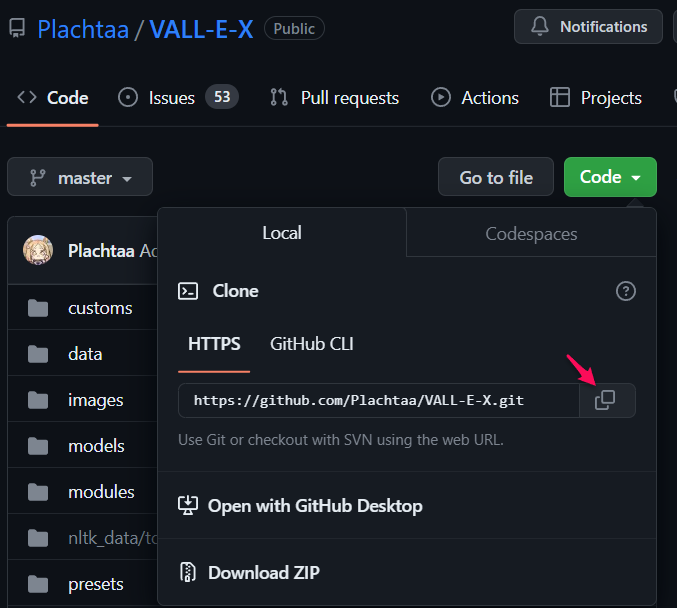
① 「Code」をクリックして、アドレスをコピーする。
② コマンドプロンプトを開き、適当なフォルダで下記コマンドを実行。
※この例では、"D:\Projects\ai"フォルダを使用しています。
D:\Projects\ai>git clone https://github.com/Plachtaa/VALL-E-X.git
③ クローンしたフォルダに移動。
D:\Projects\ai>cd VALL-E-X.git
④ オリジナル環境を汚したくないので、VENVを使って仮想環境を構築します。
※この例では、仮想環境の名前は"vall_e_x"としましたが、なんでもOKです。
D:\Projects\ai\VALL-E-X>python -m venv vall_e_x
⑤ 仮想環境をアクティベート(実行)。
D:\Projects\ai\VALL-E-X>vall_e_x\Scripts\activate
仮想環境が立ち上がると、コマンドラインの先頭に(vall_e_x)が付きます。
(vall_e_x) D:\Projects\ai\VALL-E-X>
4. PyTorch2.0
① 上記サイトにアクセスして、「Get Started」をクリック。
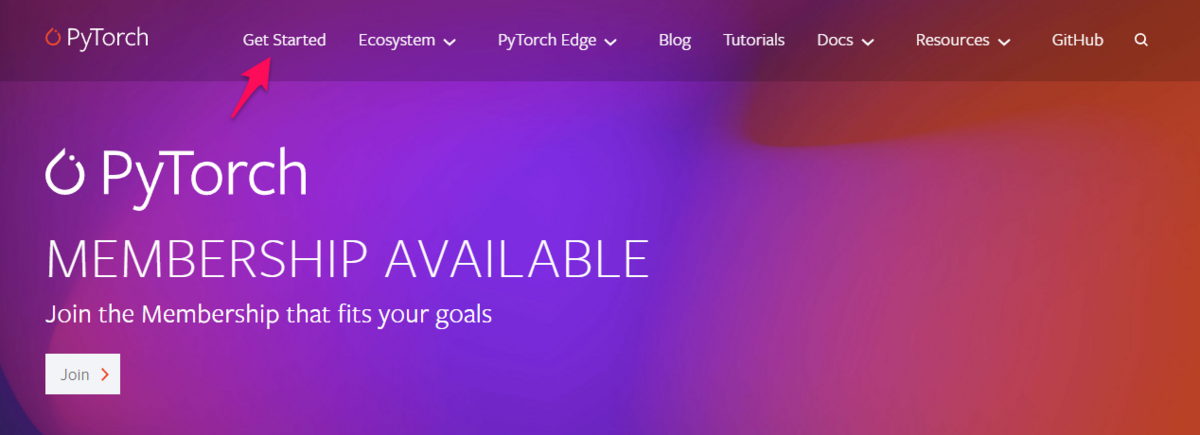
② 「Computer Platform」の「CUDA12.1」をクリックすると、「Run this Command」の表示されているコマンドをコピー。
③ コピーしたコマンドをコマンドプロンプトで実行。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
5. VALL-E-Xのライブラリ
最後の仕上げに、VALL-E-Xに必要なライブラリ群をインストールします。が、ここに罠が潜んでます。。。
ライブラリ群のインストールは下記コマンドで行います。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip install -r requirements.txt
VALL-E-Xを使う
起動!
下記コマンドでVALL-E-X(UI版)を起動します。
なお、初回起動のみ、各種データをダウンロードするようで結構時間がかかります。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
ハマりポイント
起動するとコマンドプロンプトに下記ログが表示され、エラーが発生します。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
default encoding is utf-8,file system encoding is utf-8
You are using Python version 3.10.9
Use 20 cpu cores for computing
100% [....................................................................] 1482302113 / 1482302113D:\Projects\ai\VALL-E-X\vall_e_x\lib\site-packages\torch\nn\utils\weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
100%|█████████████████████████████████████| 1.42G/1.42G [01:05<00:00, 23.2MiB/s]
Traceback (most recent call last):
File "D:\Projects\ai\VALL-E-X\launch-ui.py", line 629, in <module>
main()
File "D:\Projects\ai\VALL-E-X\launch-ui.py", line 528, in main
upload_audio_prompt = gr.Audio(label='uploaded audio prompt', source='upload', interactive=True)
File "D:\Projects\ai\VALL-E-X\vall_e_x\lib\site-packages\gradio\component_meta.py", line 146, in wrapper
return fn(self, **kwargs)
TypeError: Audio.__init__() got an unexpected keyword argument 'source'
結論から言うと、2023/11現在、graidoライブラリ(Ver.4.02)がバージョンアップされて仕様が変更されておりエラーが発生しているようです。
gradioライブラリ のAudio仕様(https://www.gradio.app/docs/audio)を確認すると、Initialization Parameterに"source"ではなく、"sources"となっています。
ということで、
素直に"Ver4.02"から、Ver3のファイナルのVer.3.41.0にダウングレードします。
ダウングレードは以下のコマンドで行います。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip install gradio==3.41.0
これで起動するようになりましたので、下記コマンドで起動しましょう。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
音声生成を楽しもう!
まずはExample
無事に起動すると、デフォルト設定しているWebブラウザが自動的に立ち上がります。
早速、Exampleを使って生成してみましょう!
UIの一番下の段の3番目をクリックしてください。
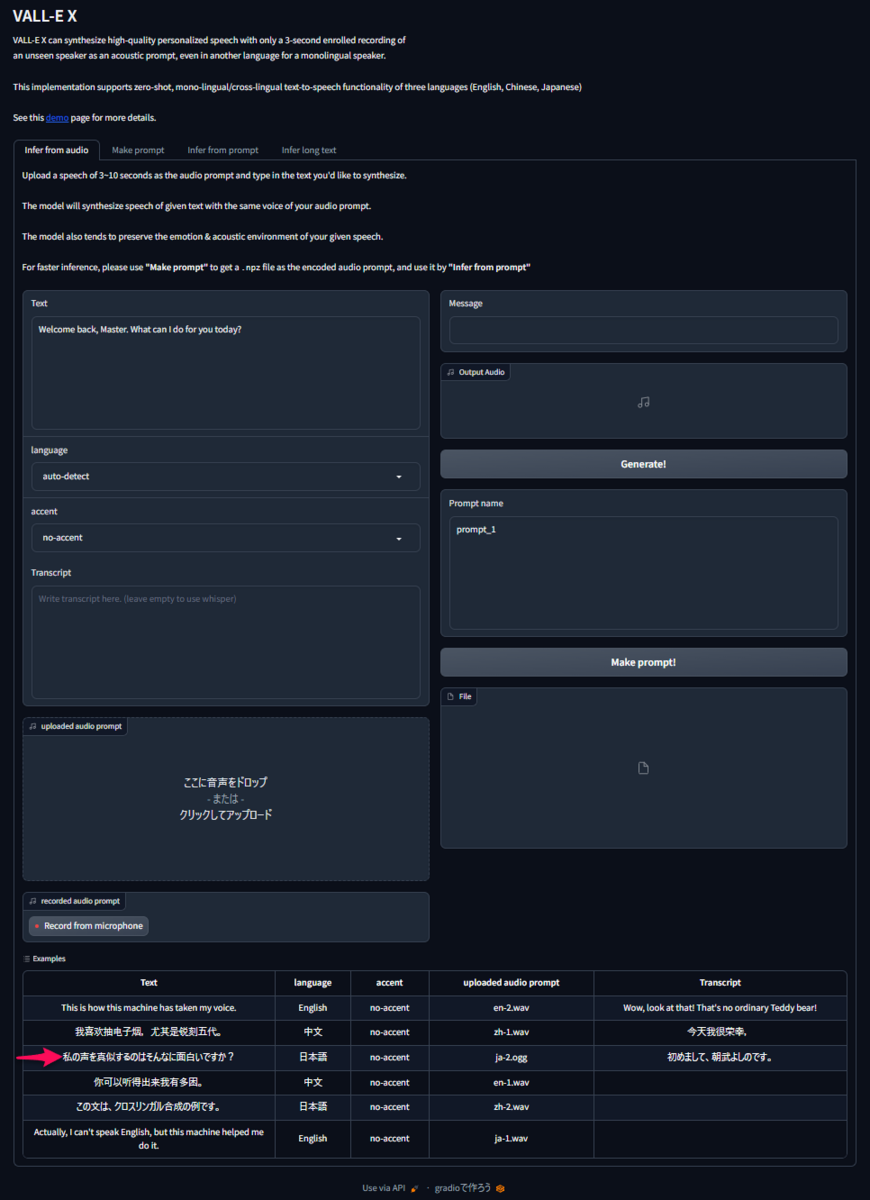
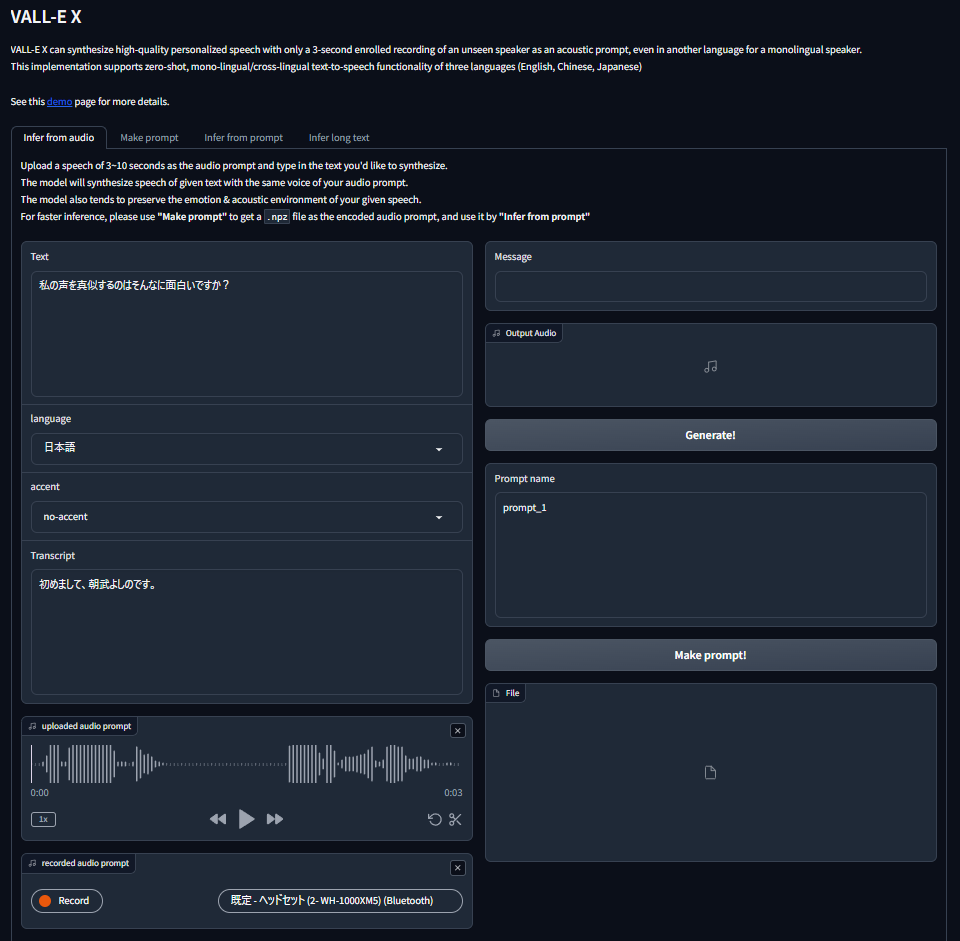
「uploaded audio prompt」にサンプル音声。「Text」に生成する言葉が自動的に設定されます。「Transcript」はサンプル音声の言葉が設定されています。
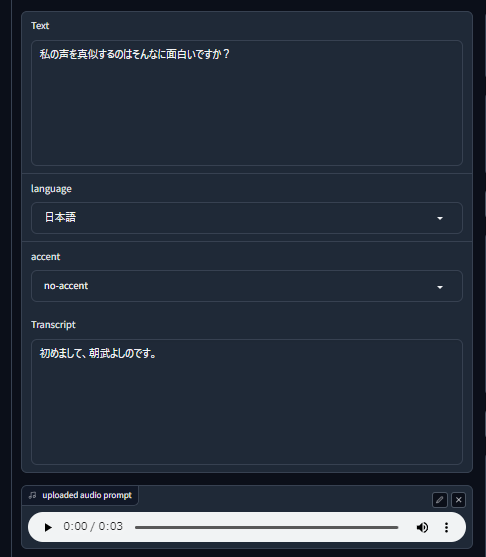
「uploaded audio prompt」の再生ボタンをクリックすると、「Transcript」に記載されている内容の音声が再生されます。
いよいよ音声生成
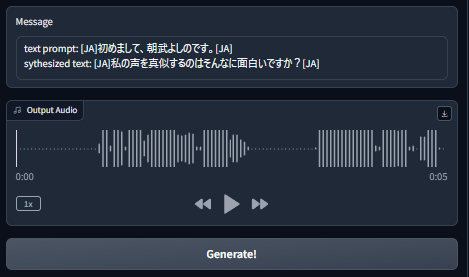
音声生成は、UI画面右上の「Generate!」ボタンをクリックします。
数秒後に、以下のように表示されるはずです。
※私の環境では、音声が途切れたりする場合がありましたが、何度か生成し直すとちゃんと変換されました。
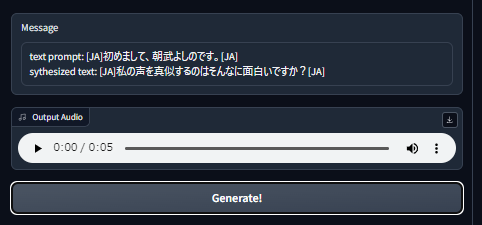
早速、再生してみましょう!!
どうですか? 「すばらし」の一言です。
生成した音声は、右上のダウンロード(下矢印)ボタンで保存できます。
他の人にもしゃべって欲しい
別の音声サンプルを使用する場合は、「uploaded audio porompt」の「x」ボタンをクリックして閉じ、wavやmp3ファイルをドラッグ&ドロップします。
効果音ラボさんのデータを使用させて頂きました。ありがとうございます!
豊富なデータが揃っていて迷いましたが、「声素材ー日常セリフ(元気な女の子)」の「間もなく、次の駅に到着いたします。お忘れ物のないようお降りください」を使用しました。
ダウンロードした、"「間もなく、次の駅に到着いたします。お忘れ物のないようお降りください」.mp3"ファイルを「uploaded audio porompt」にドラッグ&ドロップし、「Generate!」ボタンをクリックするだけです。
Whisperを使って、音声サンプルの言葉も判定しているところが素晴らしいです。
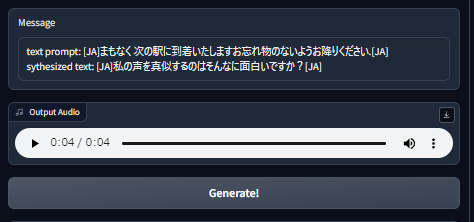
アクセントを「日本語」に切り替えると風合いが変わりますので試してみてください。

Whisperで自動認識してくれない場合は「Transcript」に手入力すると、綺麗に音声生成してくれますので、試してみてください。
あとがき
gradio のAudio仕様の問題ですが、launch-ui.pyのコードを書き換えてみました。
"source"を使用しているのは、528行、529行、561行、562行の4か所なので、お好きなエディタを使って、"souce"を"souces"に書き換えてください。
すると、gradioのAudio機能を使用している「uploaded audio prompt」、「recoded audio prompt」、「output Audio」のUI表示がアップグレードしていました。
「これはいい!!」と思ったのですが、mp3やwavファイルの読み込みができませんでした。。。
この辺りは、VALL-E-Xとライブラリのバージョン仕様の違いによるものなので、あきらめるか、自力で修正するしかなさそうです。
基本的な説明のみでしたが、皆様のお役に立てればと思います (^^)b
くれぐれも「悪用」はご控えくださいね。
Stable diffusionのOpenPose Editorを使ってみた
存在は知りつつも使っていなかった「OpenPose Editor」を使ってみるとかなり便利だったので備忘ログに残します。

目次
OpenPose Editorとは
ControlNetのOpenPoseの「棒人間」を編集することができる機能です。
「棒人間」の各ポイントを移動させることで、手腕足の位置や角度、顔の向きなどを任意に変えることができ、好みのポーズを取らせることができるようになります。
インストール
ControlNet未導入の方
前提条件として、ControlNetがインストールされている必要がありますので、インストールされていない方は下記備忘ログを参考にしてください。
ControlNet導入済みの方
OpenPose EditorのGitHubは以下に公開されています。
インストールは以下の手順で行います。
①「Extensions」タブをクリック
②「Install from URL」をクリック

③「URL for extention's git repository」に下記のGitHubのアドレスを入力
④「Install」ボタンをクリック

念のために、一旦、Stable Diffuion Web UIを再起動してください。
再起動後、タブの一覧に「OpenPose Editor」が追加されていれば無事にインストール完了です。

もし、追加されていない場合は、インストールに失敗している可能性がありますので、上記手順の④の箇所でURLが間違っていないか、通信エラー表示の有無を確認してください。
Tips.
インストールに失敗すると下記フォルダが残っているケースがますので、このフォルダを削除してから再度インストールを行ってください。このフォルダーが残ったままだとインストールが何度も失敗します。
stable-diffusion-webui mpopenpose-editor
使い方
先ずは、基本となる画像を生成しましょう。
モデルは、breakdomain_M2000を使用しました。
Prompt:
best quality, masterpiece,pleased,full-body,hatune miku, white background,Negative prompt:easynegative, nsfw, badhandv4

真正面を向かせる
①「OpenPose Editor」タブをクリック
②「Add」ボタンをクリック
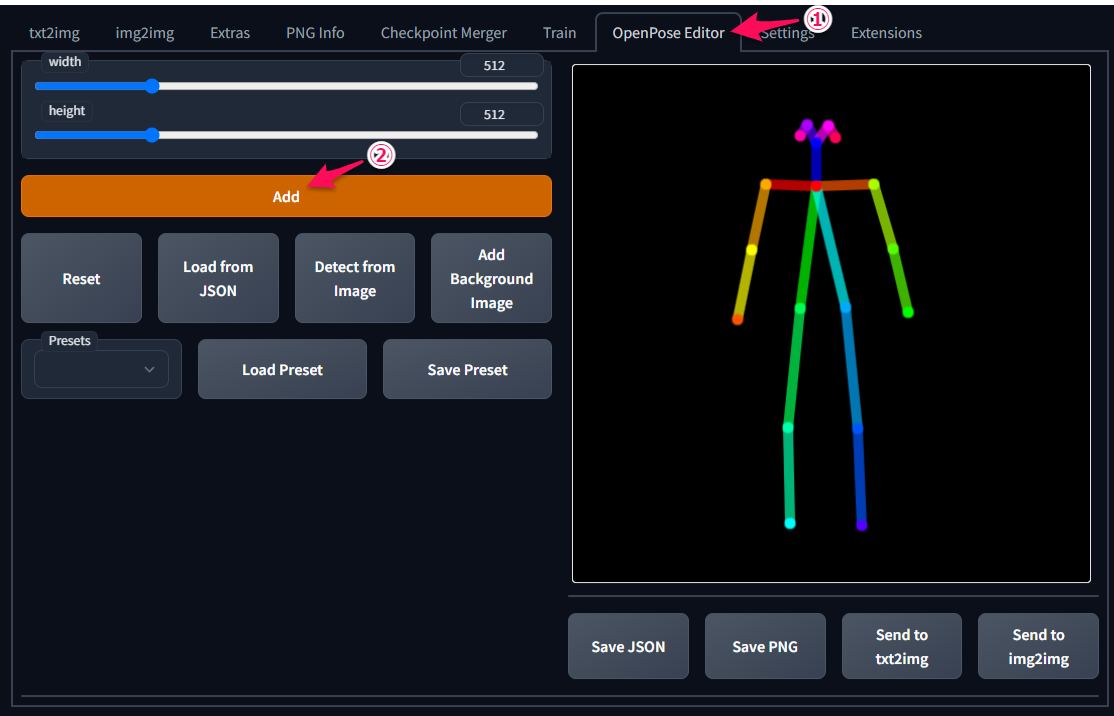
③「Send to txt2img」ボタンをクリック
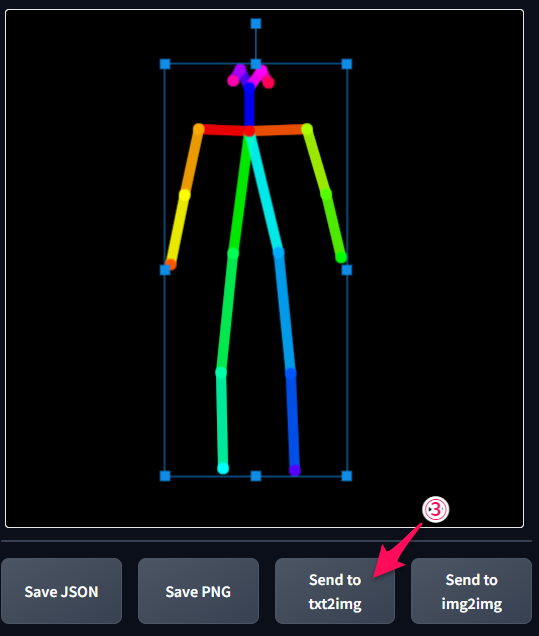
「txt2img」タブの「ControlNet」の▼をクリック
④「Enable」をチェック
⑤「Pixel Perfect」をチェック
⑥「Prepocessor」は「none」を指定 ※ここ重要です
⑦「Model」は「control_v11p_sd15_openpose」を指定 ※ここ重要です

設定完了後、「Generate」ボタンをクリックして作画します。
なんということでしょう! ミクさんが「棒人間」と同じ格好をしてますね!!

片腕を上げる
「OpenPose Editor」タブをクリックして「棒人間」の腕の丸いポイントをマウスで移動させます。そして、「Send to txt2img」ボタンをクリックして、変更内容をControlNet側に反映させます。
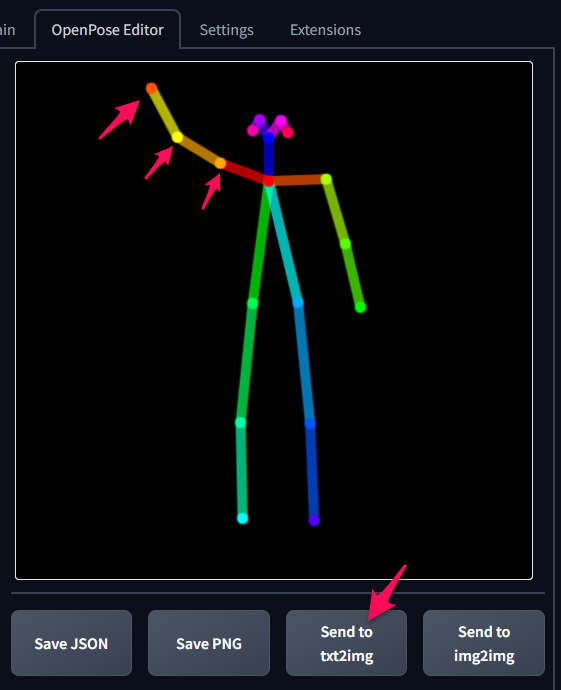
次に、「Generate」ボタンをクリックして作画します。
ちゃんと「棒人間」と同じポーズになってますね(^^♪

顔や足の向きを変える
触覚のような頭部分は、以下のように各部位に対応しています。
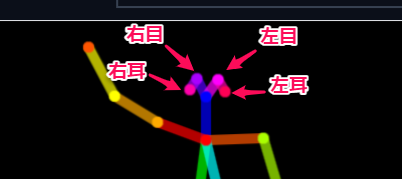
ですので、以下のようにすると動きのあるポーズをとらせることができます。

顔の向きもちゃんと変わってますね (^^)

あとがき
ControlNetを使えば元画像のポーズを抽出することはできますが、目的のポーズを探すのも大変です。「OpenPose Editor」を使えば、イメージ通りのポーズで作画をできるため時短もでき、とても有用なツールです。
超基本的な説明のみでしたが、皆様のお役に立てればと思います (^^)b
Stable diffusionのfractal artプロンプトを色々試してみた
最近お気に入りの"fractal art"プロンプトについて色々試した結果の備忘ログです。

目次
フラクタルアートとは
フラクタルアートは、幾何学的な図形や色彩の組み合わせによって独特な視覚効果を生み出してくれます。
簡単なプロンプトで画像生成してみるとこんな感じです。
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(fractal art:1.4),

"fractal art"プロンプトの前に組み込みたい画像を追加すると、面白い画像が生成できます。以下にいくつかの例を示します。
モデルは、breakdomain_M2000を使用しました。
Flower(花)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(flower fractal art:1.3), girl

Water(水)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,(water droplets fractal art:1.4),girl

Origami(折り紙)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(origami fractal art:1.4), girl

Beads(ビーズ)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(beads fractal art:1.4), girl

Ivy(ツタ)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(ivy fractal art:1.4), girl

Ice(氷)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(ice fractal art:1.4), girl

Snow(雪)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(snow fractal art:1.4), girl

Fireworks(花火)
close-up,masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2,
(firework fractal art:1.4), girl

あとがき
fractal artプロンプトの影響度(1.4の部分)でフラクタルアートの効き具合を調整できますので、いろいろ変えてみるのも楽しいです。(^^)b
Stable diffusionのLoRAにLyCORISを追加したらLoRAが効かなくなった時の対処メモ
LyCORIS(LoHa, LoCon)を使ってみたくてインストールしたら、今まで使っていたLoRAが効かなくなった時の対処メモです。

目次
状況
条件:LyCORIS(a1111-sd-webui-locon)はインストール済みとします。
LoRA:お気に入りの「うる星やつら」です。
単純な下記プロンプトで画像生成してみると。。
lum<lora:lumUruseiYatsura_10:1>Negative prompt: easynegative, nsfwSteps: 20, Sampler: Euler a, CFG scale: 7, Seed: 1224755484, Size: 512x512, Model hash: ab3284a3d6, Model: pastelLinesMix_pastelLinesMix10

思ってたのと違う画像が生成されてしまいました。。。
LyCORIS(a1111-sd-webui-locon)インストール直後だったので、とりあえず、「Extensions」タブの「a1111-sd-webui-locon」チェックを外し「Apply and restart UI」をクリックして機能を無効にしてみました。

残念ながら、生成される画像は変わらず。。。
対策
LyCORIS(a1111-sd-webui-locon)がインストールされている下記フォルダを消す、又はデスクトップなどに移動させて、webuiを再起動することで元に戻りました。
\stable-diffusion-webui\extensions\a1111-sd-webui-locon

なお、再度、LyCORIS(a1111-sd-webui-locon)を使用する場合は、フォルダを元に戻せばOKです。
あとがき
何故このような状態になったかは不明ですが、LyCORISが従来のLoRAに影響を与えるケースもあるようです。
もし、過去にLoRAを使用して作成した画像が再現できない場合などにお役に立てればと思います。 (^^)b
Stable diffusionのLoRAタブが消えた時の対処メモ
ある日、花札アイコンをクリックした時にLoRAタブが消えてて焦って対処した際のメモです。

目次
状況
①花札アイコンをクリック
②LoRAタブが無い!

原因
「ControlNet」アップデート時、「Lora」チェックを外して作業していた。
私の場合、下記の手順でアップデートしてました。
①「ControlNet」以外のExtension(LoRAなど)のチェックを外す
②「Click for updates」をクリック
③「Apply and restart UI」をクリック

このアップデート後にLoRAタブが消えてました。。
対策
①「ControlNet」以外のExtension(LoRAなど)のチェックを入れる
②「Click for updates」をクリック
③「Apply and restart UI」をクリック

④花札アイコンをクリックしてLoRAタブが表示されるか確認

もし、LoRAタブが表示されていない場合は、webuiを再起動してみてください。
あとがき
アップデートに不要な項目なのでチェックを外して作業したのが原因とは驚きました。
この対策は一例かもしれませんが、LoRAや他のExtensionが無効になってしまった時などにお役に立てればと思います。 (^^)b