VALL-E-X(音声生成AI)が気になったので使ってみた
音声生成AIの「VALL-E-X」の基本機能の確認とハマりポイントがありましたので備忘ログに残します。

目次
インストール
下記アプリケーションやライブラリをインストールします。
なお、Windows11を前提に作業を進めます。
- FFmpeg
- CUDA12
- VALL-E-X
- PyTorch2.0
1. FFmpeg
下記サイトからWindows版のFFmpgeをダウンロードします。
ffmpeg.org
Windowsを選択し、「Windows builds by Btbn」をクリック。
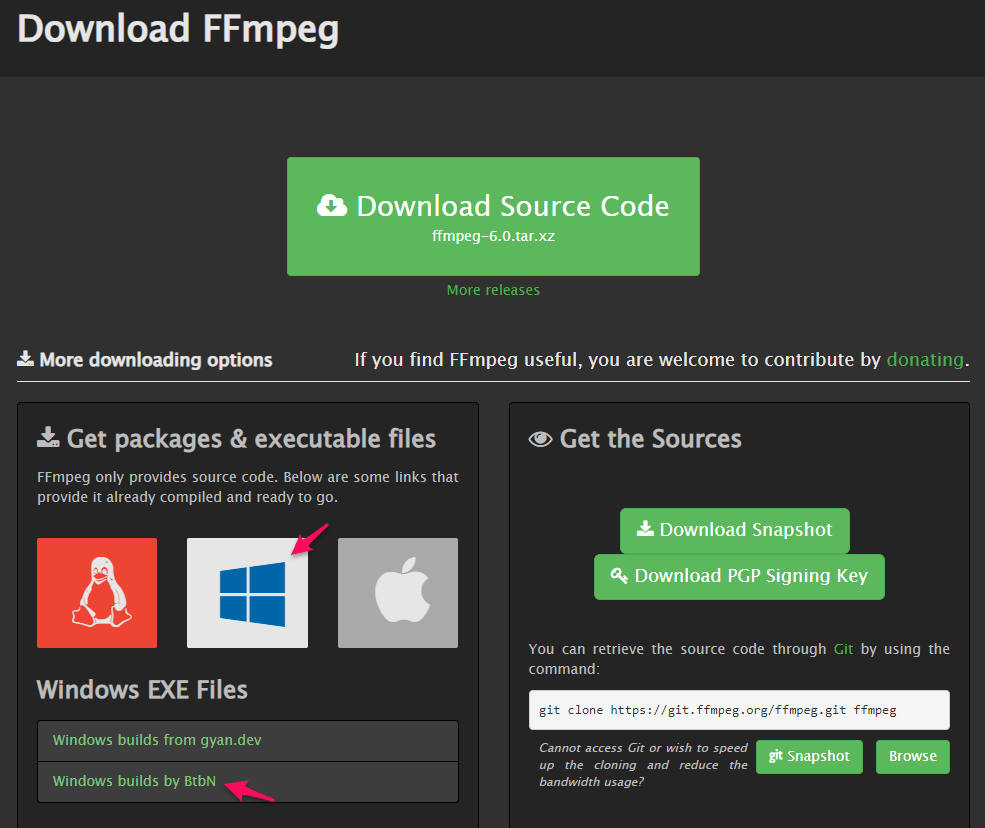
「ffmpeg-master-latest-win64-gpl.zip」をクリックしてダウンロード。
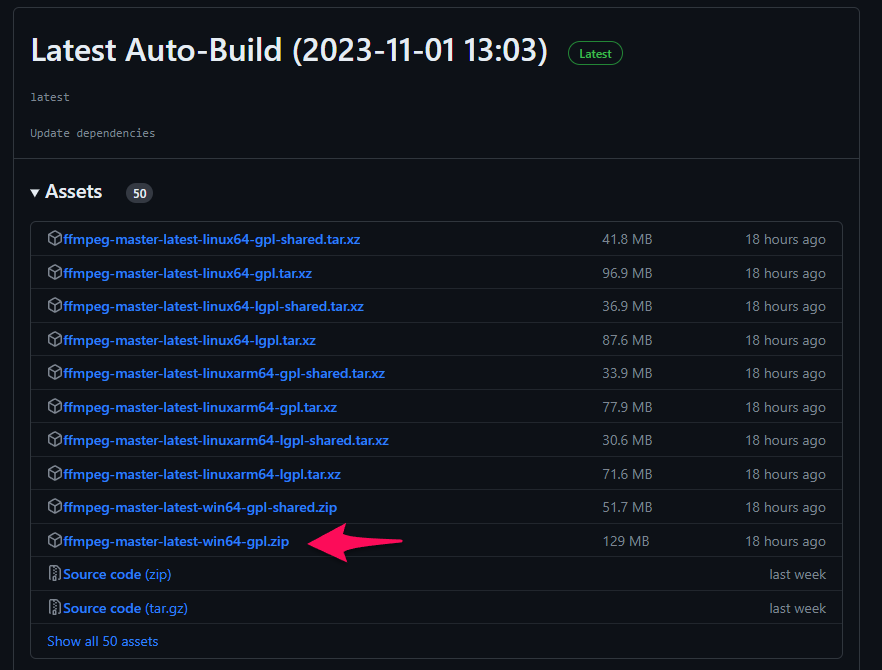
ダウンロードしたファイルを展開(解凍)します。
展開すると、「ffmpeg-master-latest-win64-gpl」フォルダ内に下記ファイル類が生成されていることを確認してください。
ffmpeg-master-latest-win64-gplを適当なフォルダに移動させてパスを通します。パスの通し方は「環境変数」の「Path」に「ffmpeg-master-latest-win64-gpl」を設定します。
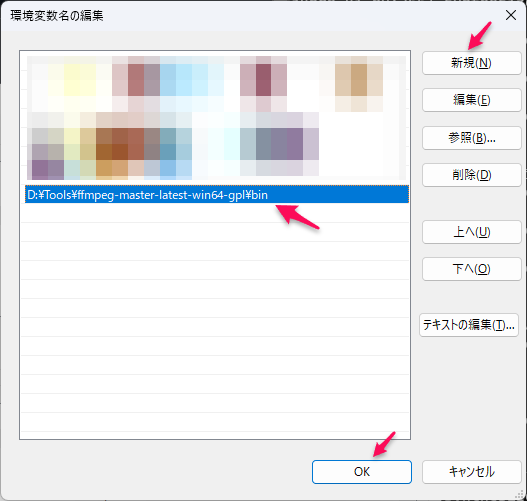
まず、「環境変数の編集」を開き、「環境変数」の「編集」ボタンをクリック。
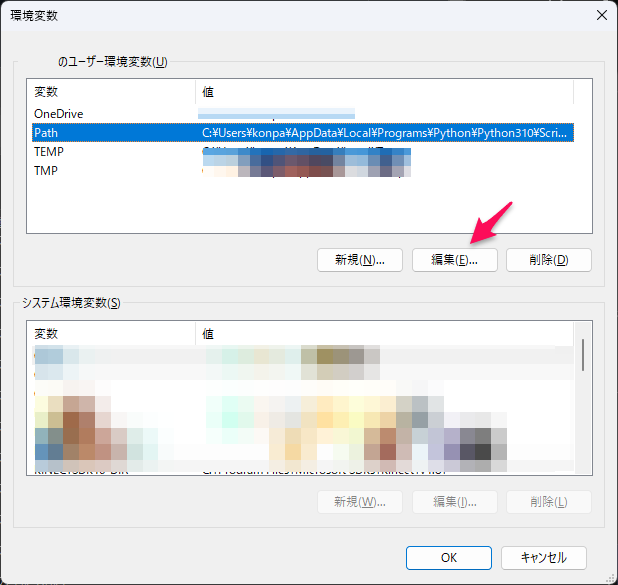
「環境変数名の編集」ダイアログにて、「新規」ボタンをクリックして、ffmpegのフォルダを追加し、「OK」ボタンをクリック。ffmpegフォルダ名は「bin」まで必要なので注意してください。
2. CUDA12.0
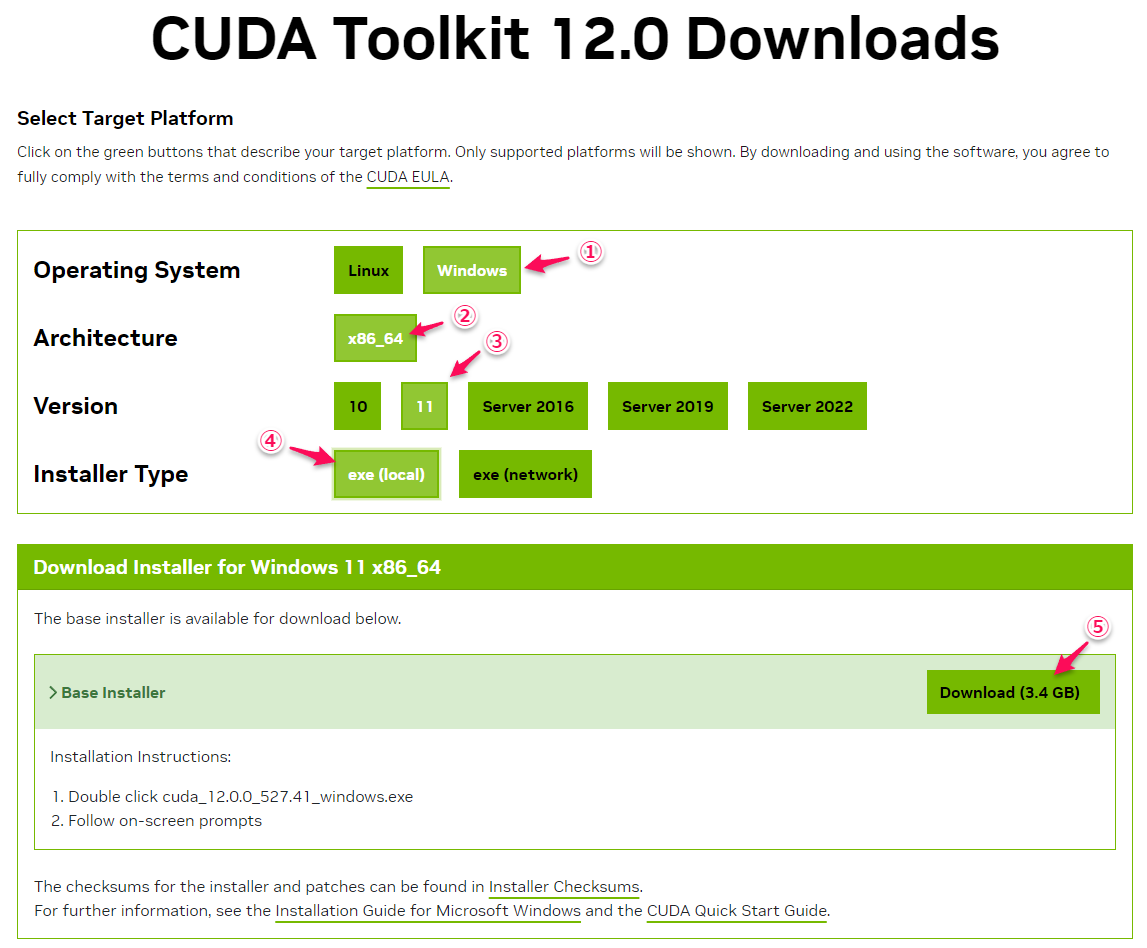
nvidia公式のCUDA Toolkit 12をダウンロード。
http:// https://developer.nvidia.com/cuda-12-0-0-download-archive
① 「Windows」をクリック
② 「x86_64」をクリック
③ 「11」をクリック(Windows11なので)
④ 「exe (local)」をクリック ※networkを選択しても問題ありません
⑤ 「Download(3.4GB)」をクリック ※大きいですね (^^;
あとは、ダウンロードしたファイルを実行するだけでOKです。
3. VALL-E-X
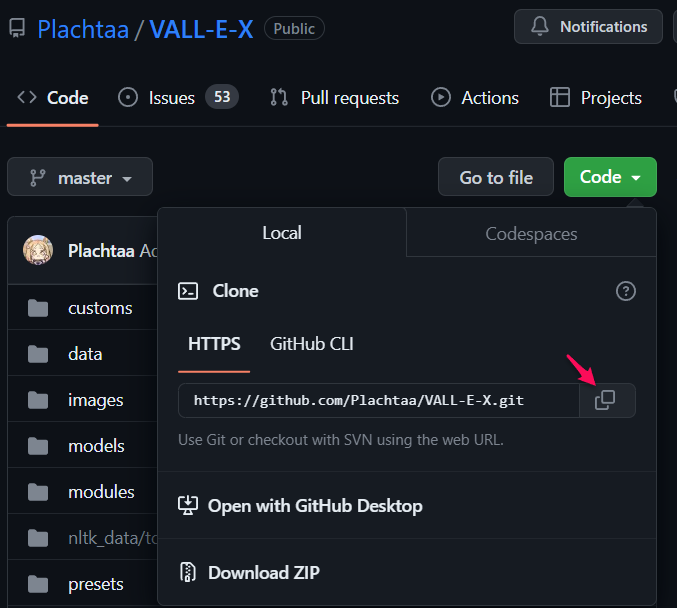
以下のGitHUBからファイル一式をクローンします。
① 「Code」をクリックして、アドレスをコピーする。
② コマンドプロンプトを開き、適当なフォルダで下記コマンドを実行。
※この例では、"D:\Projects\ai"フォルダを使用しています。
D:\Projects\ai>git clone https://github.com/Plachtaa/VALL-E-X.git
③ クローンしたフォルダに移動。
D:\Projects\ai>cd VALL-E-X.git
④ オリジナル環境を汚したくないので、VENVを使って仮想環境を構築します。
※この例では、仮想環境の名前は"vall_e_x"としましたが、なんでもOKです。
D:\Projects\ai\VALL-E-X>python -m venv vall_e_x
⑤ 仮想環境をアクティベート(実行)。
D:\Projects\ai\VALL-E-X>vall_e_x\Scripts\activate
仮想環境が立ち上がると、コマンドラインの先頭に(vall_e_x)が付きます。
(vall_e_x) D:\Projects\ai\VALL-E-X>
4. PyTorch2.0
① 上記サイトにアクセスして、「Get Started」をクリック。
② 「Computer Platform」の「CUDA12.1」をクリックすると、「Run this Command」の表示されているコマンドをコピー。
③ コピーしたコマンドをコマンドプロンプトで実行。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
5. VALL-E-Xのライブラリ
最後の仕上げに、VALL-E-Xに必要なライブラリ群をインストールします。が、ここに罠が潜んでます。。。
ライブラリ群のインストールは下記コマンドで行います。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip install -r requirements.txt
VALL-E-Xを使う
起動!
下記コマンドでVALL-E-X(UI版)を起動します。
なお、初回起動のみ、各種データをダウンロードするようで結構時間がかかります。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
ハマりポイント
起動するとコマンドプロンプトに下記ログが表示され、エラーが発生します。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
default encoding is utf-8,file system encoding is utf-8
You are using Python version 3.10.9
Use 20 cpu cores for computing
100% [....................................................................] 1482302113 / 1482302113D:\Projects\ai\VALL-E-X\vall_e_x\lib\site-packages\torch\nn\utils\weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
100%|█████████████████████████████████████| 1.42G/1.42G [01:05<00:00, 23.2MiB/s]
Traceback (most recent call last):
File "D:\Projects\ai\VALL-E-X\launch-ui.py", line 629, in <module>
main()
File "D:\Projects\ai\VALL-E-X\launch-ui.py", line 528, in main
upload_audio_prompt = gr.Audio(label='uploaded audio prompt', source='upload', interactive=True)
File "D:\Projects\ai\VALL-E-X\vall_e_x\lib\site-packages\gradio\component_meta.py", line 146, in wrapper
return fn(self, **kwargs)
TypeError: Audio.__init__() got an unexpected keyword argument 'source'
結論から言うと、2023/11現在、graidoライブラリ(Ver.4.02)がバージョンアップされて仕様が変更されておりエラーが発生しているようです。
gradioライブラリ のAudio仕様(https://www.gradio.app/docs/audio)を確認すると、Initialization Parameterに"source"ではなく、"sources"となっています。
ということで、
素直に"Ver4.02"から、Ver3のファイナルのVer.3.41.0にダウングレードします。
ダウングレードは以下のコマンドで行います。
(vall_e_x) D:\Projects\ai\VALL-E-X>pip install gradio==3.41.0
これで起動するようになりましたので、下記コマンドで起動しましょう。
(vall_e_x) D:\Projects\ai\VALL-E-X>python launch-ui.py
音声生成を楽しもう!
まずはExample
無事に起動すると、デフォルト設定しているWebブラウザが自動的に立ち上がります。
早速、Exampleを使って生成してみましょう!
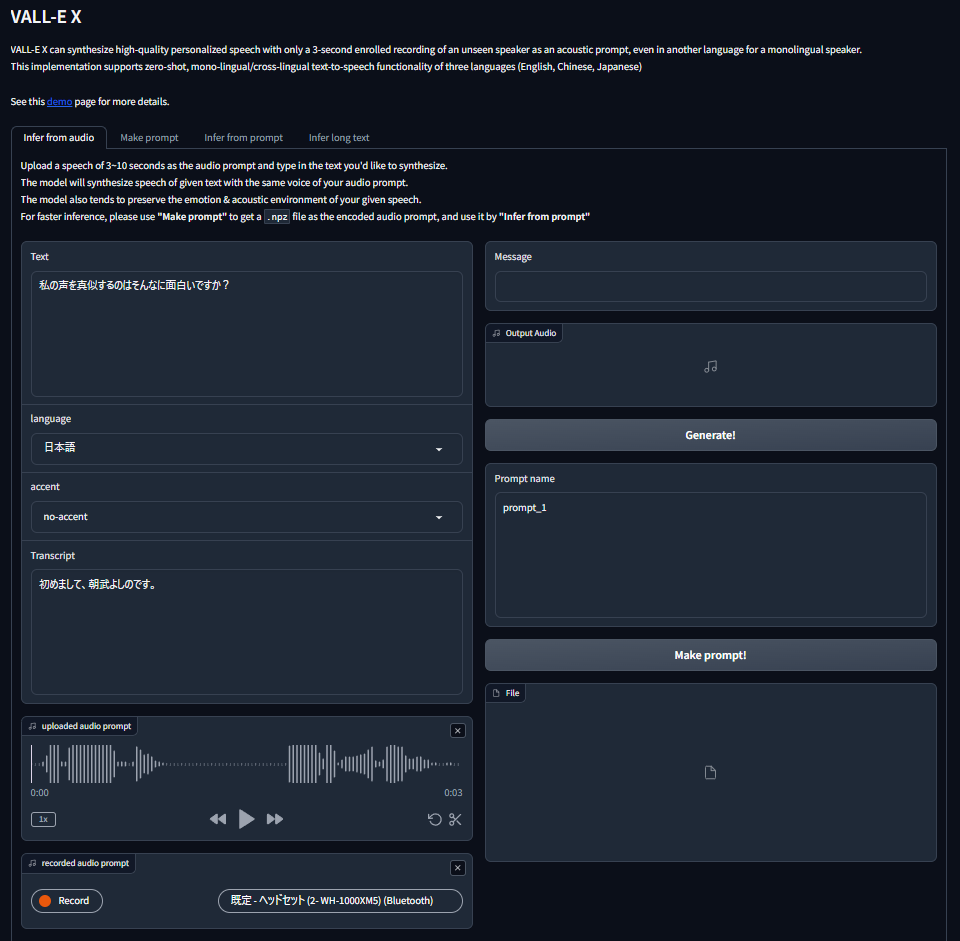
UIの一番下の段の3番目をクリックしてください。
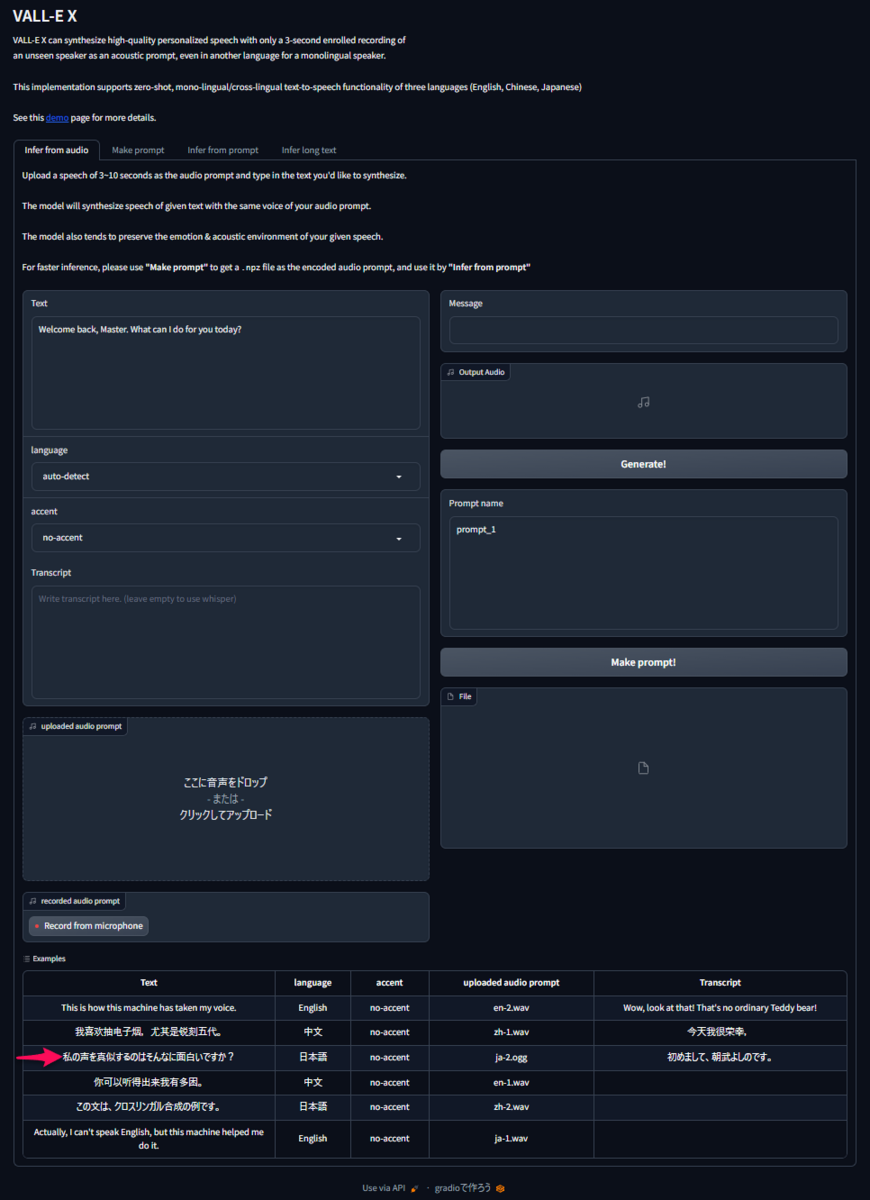
「uploaded audio prompt」にサンプル音声。「Text」に生成する言葉が自動的に設定されます。「Transcript」はサンプル音声の言葉が設定されています。
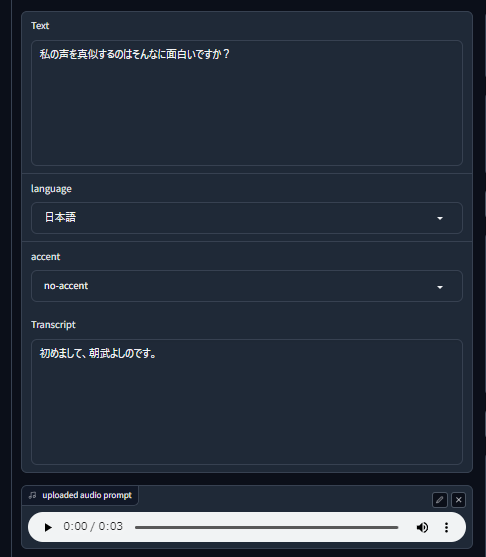
「uploaded audio prompt」の再生ボタンをクリックすると、「Transcript」に記載されている内容の音声が再生されます。
いよいよ音声生成
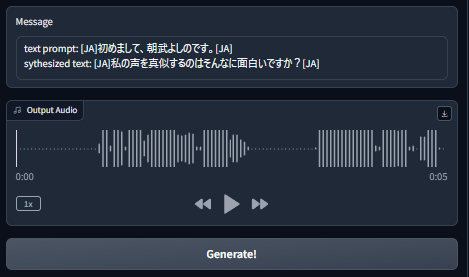
音声生成は、UI画面右上の「Generate!」ボタンをクリックします。
数秒後に、以下のように表示されるはずです。
※私の環境では、音声が途切れたりする場合がありましたが、何度か生成し直すとちゃんと変換されました。
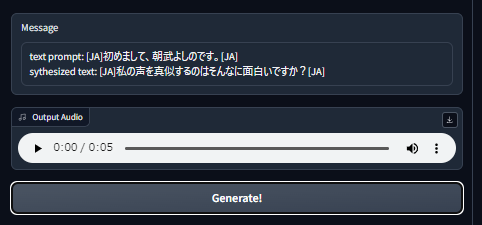
早速、再生してみましょう!!
どうですか? 「すばらし」の一言です。
生成した音声は、右上のダウンロード(下矢印)ボタンで保存できます。
他の人にもしゃべって欲しい
別の音声サンプルを使用する場合は、「uploaded audio porompt」の「x」ボタンをクリックして閉じ、wavやmp3ファイルをドラッグ&ドロップします。
効果音ラボさんのデータを使用させて頂きました。ありがとうございます!
豊富なデータが揃っていて迷いましたが、「声素材ー日常セリフ(元気な女の子)」の「間もなく、次の駅に到着いたします。お忘れ物のないようお降りください」を使用しました。
ダウンロードした、"「間もなく、次の駅に到着いたします。お忘れ物のないようお降りください」.mp3"ファイルを「uploaded audio porompt」にドラッグ&ドロップし、「Generate!」ボタンをクリックするだけです。
Whisperを使って、音声サンプルの言葉も判定しているところが素晴らしいです。
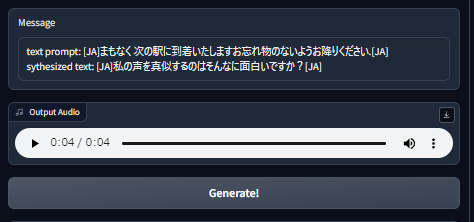
アクセントを「日本語」に切り替えると風合いが変わりますので試してみてください。

Whisperで自動認識してくれない場合は「Transcript」に手入力すると、綺麗に音声生成してくれますので、試してみてください。
あとがき
gradio のAudio仕様の問題ですが、launch-ui.pyのコードを書き換えてみました。
"source"を使用しているのは、528行、529行、561行、562行の4か所なので、お好きなエディタを使って、"souce"を"souces"に書き換えてください。
すると、gradioのAudio機能を使用している「uploaded audio prompt」、「recoded audio prompt」、「output Audio」のUI表示がアップグレードしていました。
「これはいい!!」と思ったのですが、mp3やwavファイルの読み込みができませんでした。。。
この辺りは、VALL-E-Xとライブラリのバージョン仕様の違いによるものなので、あきらめるか、自力で修正するしかなさそうです。
基本的な説明のみでしたが、皆様のお役に立てればと思います (^^)b
くれぐれも「悪用」はご控えくださいね。